Inventory.data.gov Guide
Introduction
Inventory.data.gov is a data management tool established in 2013 by the Data.gov Program Management Office (PMO) in what is now the Technology Transformation Service of the U.S. General Services Administration (GSA). Inventory.data.gov supports the implementation of the 2013 Federal Open Data Policy (M-13-13) by providing all of the relevant metadata fields and export formats required for agencies to have their data harvested by Data.gov and to comply with the Federal Open Data Policy. Inventory.data.gov is not required to be used by all agencies, but rather offered in order to assist agencies that do not have another solution for creating and maintaining data inventories.
The platform is primarily used to generate two different data.json files for each agency, one representing the Unredacted Inventory / Enterprise Data Inventory (EDI) that contains unredacted datasets and another representing the Redacted Inventory / Public Data Listing (PDL) that contains datasets with redactions as agency indicated. The Unredacted Inventory/EDI file is a comprehensive inventory for an agency. This file is sent directly to omb.max.gov and not publicly accessed. The Redacted Inventory/PDL file (often referred to as data.json) is made public and is posted on agency.gov/data.json and harvested by the Data.gov catalog.
The Data.gov catalog is based on CKAN (Comprehensive Knowledge Archive Network), an open source technology that powers many government open data sites. Inventory.data.gov is a separate instance of CKAN hosted at GSA on the same infrastructure as the Data.gov catalog. To avoid confusion, neither site should simply be referred to as the “CKAN site”, but instead by the full URL.
This guide describes the features available through inventory.data.gov and provides instructions for agencies interested in using inventory.data.gov for dataset management. At the current level of usage, Data.gov/GSA has been able to provide inventory.data.gov to interested agencies at no cost. This could change in the future with expanded usage and services.
Inventory.data.gov as a dataset management system requires a user account and is not publicly accessible (with the exception of a few datasets that are hosted on inventory.data.gov, discussed in more detail below). Inventory.data.gov allows the registered users to manage the datasets for their agency only.
Features
Inventory.data.gov provides the following features for dataset management/Open Data Policy compliance purposes:
- Existing data.json and enterprise data inventory metadata can be imported directly into inventory.data.gov.
- User group organizations can be created either for an entire agency or for individual bureaus so that users and permissions can be managed and delegated as needed by the agency
- A platform to manage public/non-public datasets: create new entries, modify existing ones, and delete any datasets as needed
- Unredacted Inventory / Enterprise Data Inventory (EDI) and Redacted Inventory / Public Data Listing (PDL) functionality exports the successfully validated datasets in the form of a data.json file complying to the POD Schema 1.1 version. Error records are provided in a log file for review and resolution by agency users.
Using inventory.data.gov
Once an agency has consulted with the Data.gov PMO and has decided to use inventory.data.gov for dataset management, the next steps are:
-
Setting up an “organization” on inventory.data.govFirst, the agency should decide how they want to present their structure within inventory.data.gov. An agency could make the “organization” the entire agency (for example, make the entire Department of Veterans Affairs one “organization). In that case, everyone with a user account associated to VA on inventory.data.gov would be able to view, add, edit or delete datasets for all of VA within inventory.data.gov. An agency could create an “organization” for sub-agencies, for instance creating an organization for the Farm Service Agency and all the other units of the Department of Agriculture. In that scenario, a user account for Farm Service Agency could view, add, edit or delete datasets for the Farm Service Agency only.The Data.gov PMO will set up organizations in the manner requested by the agency.
-
Migrating existing datasets to inventory.data.govMost agencies have already created data inventories pursuant to the Open Data Policy. To begin using inventory.data.gov to manage the datasets, the Data.gov team will migrate the existing data listings to inventory.data.gov so that agencies can start editing from the current versions. For agencies that do not have data inventories under the Open Data Policy, but do have datasets listed in the current Data.gov catalog from the old Dataset Management System, the Data.gov PMO can migrate these old listings into inventory.data.gov for the agencies to update.
-
Creating user accounts for the agency representatives who will be using inventory.data.gov to manage the agency datasets.Inventory.data.gov, for dataset management purposes, is not publicly accessible. Users must have accounts on the system. There are three levels of accounts for any “organization” on inventory.data.gov: Administrator, Editor, and Member. For dataset management, agency users will either have an Administrator or Editor account. Agencies should appoint at least one Administrator. Administrators can add additional members from that agency (organization), including additional Administrators.Agencies should nominate the Administrator(s). The Data.gov PMO will create these accounts and ensure that the Administrators are familiar with the process of adding additional Administrators and Members for their agency (organization).
Creating a User Account
Logins to use inventory.data.gov are integrated with OMB MAX login. You should log in to OMB MAX using your OMB MAX credentials on your first use of inventory.data.gov.
Two-factor authentication (2FA) is now required, so enable 2FA through the instructions on the OMB MAX login page. You can add a device by clicking on “Manage SMS 2-Factor Devices” under your profile settings. This is not necessary if you use your PIV/CAC card to log in to MAX; it is already considered 2FA.
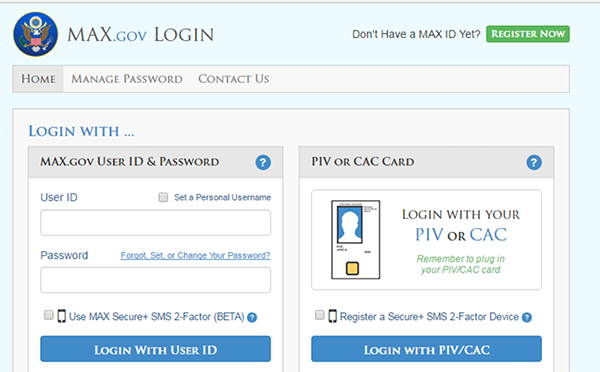
After you have logged in to OMB MAX, email us to let us know you have completed the initial login, in the email provide the organization name and access permission (Admin or Editor) required. We will then associate requested permissions to your account. On subsequent logins to inventory.data.gov (through OMB MAX), you should be able to use inventory.data.gov to manage metadata without further assistance.
Using inventory.data.gov to manage datasets
Once you have an account as an Editor or Administrator for your agency (Organization), you can use inventory.data.gov to add or edit datasets for your Organization.
Once you log in, you’ll see an activity page showing your recent activity on inventory.data.gov.
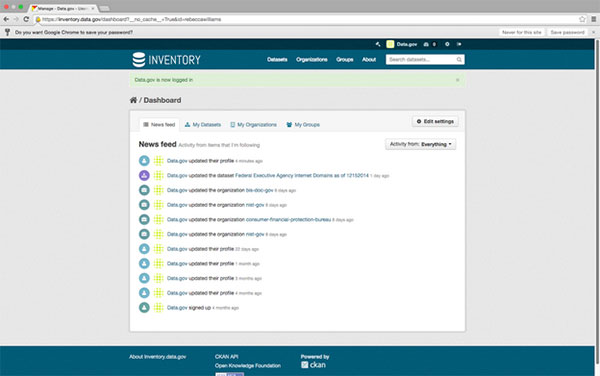
The main tabs you will be using are “Datasets” and “Organizations.”
Datasets:
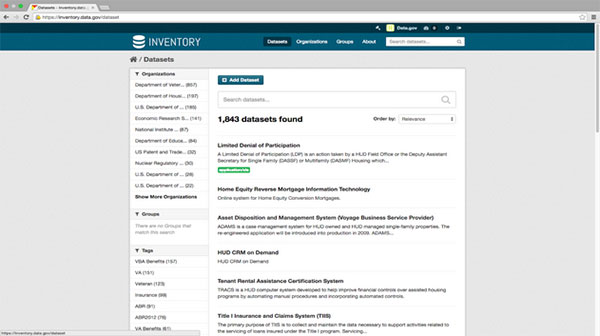
Organizations:
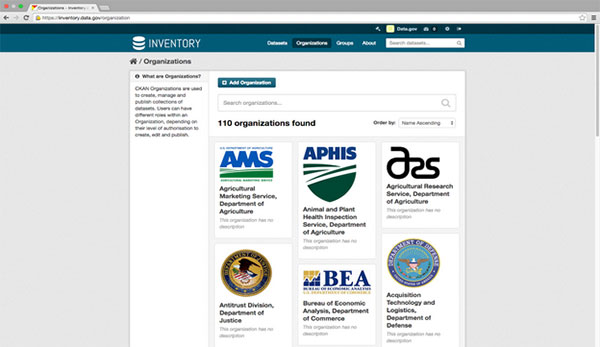
When you click on the “Organizations” tab, you’ll go to the main Organizations page that lists all the Organizations in inventory.data.gov. To find your Organization, you can search for it in the search bar on the page.
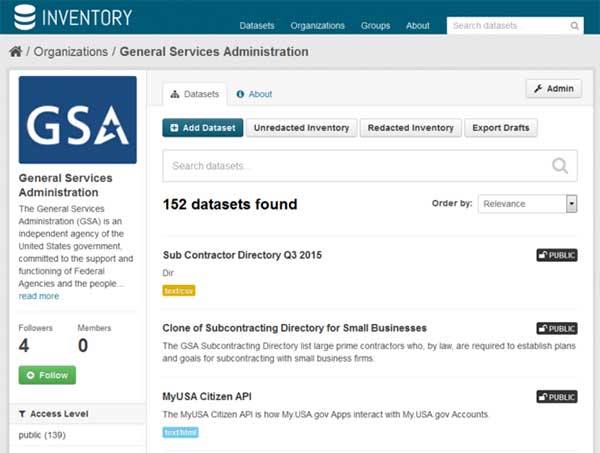
When you click on your Organization, all the datasets for the Organization will be displayed.
There’s an Admin button on the upper right for Administrators. By clicking on it, you get the main information about the Organization, including a tab for “Members.”
Clicking on “Members” brings up all the Members of the Organization who can add and edit datasets. Clicking on the Add Members button gives you the option of adding an existing user of inventory.data.gov to your Organization. Before you can add Members to your organization, the new Member has to complete initial log in on inventory.data.gov using the OMB MAX, 2FA or PIV authentication.
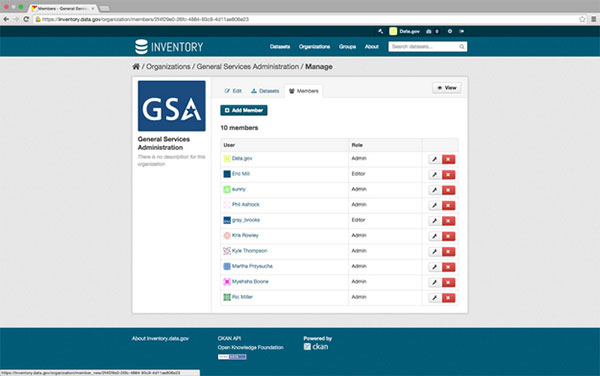
There are three levels of access. Member is read only access. Editor allows you to add and edit datasets. Admin can perform the same actions as an Editor and also add members to the Organization.
Adding a Dataset
Click on the Dataset tab.
Then click on Add a Dataset. That takes you to the Create Dataset page.
The Create Dataset page features the metadata following the Project Open Data metadata schema version 1.1.
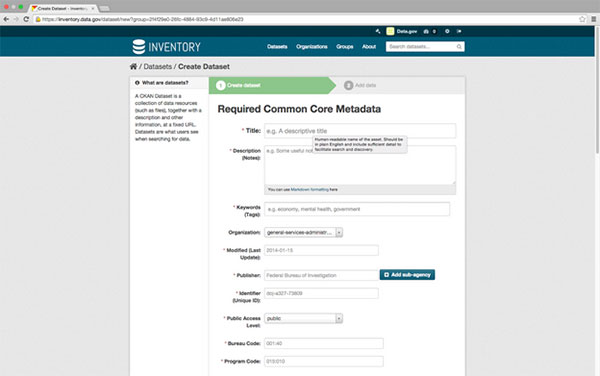
There are examples displayed in each field, and there is also pop-up help information for each field. Full details are on the Project Open Data page. Fields marked by the red asterisk are required.
There is validation for each field, so if you try to skip a required field or enter improper formats for a particular field, you’ll get an error message when you try to add the dataset.
Entering Metadata
Enter the Title for the dataset, as you would like the Title to be displayed.
The URL for the dataset will be generated automatically based on the Title.
Enter the Description for the dataset as a summary about the dataset.
Enter the Keywords for the dataset. Your dataset will be included when a Data.gov user searches for those keywords.
Modified/Last Update – most recent date on which the dataset was changed, updated or modified
For Publisher, enter the name of your agency. Use the Add sub-agency button to enter a sub-agency to more specifically identify the source of the dataset. These additional sub-agency fields are optional.
Access Level: Choose public, restricted public, or non-public. All type of “Access Level” datasets are now included in both Redacted Inventory (PDL) and Unredacted Inventory (EDI), The redaction feature is not available for public datasets, but is available for restricted public and non-public datasets. In editing metadata for restricted public and non-public datasets, the applicable individual fields can be fully or partially redacted.
See the Redaction and Partial Redaction feature for more information.
Bureau Code/Program Code. These are required fields following specific formats. Your agency POC should have this information. See the Project Open Data page for more information about these fields.
Contact Name/Email. Enter the name and email information for the contact for this dataset. Questions about this dataset will be referred to the contact listed.
There are several Required If Applicable fields that are optional. Example text is provided in each field.
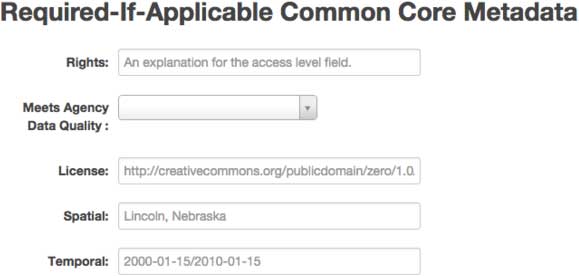
Rights. You have the option to enter a short explanation for why the value in the Access Level field was selected here.
Meets Agency Data Quality. This field shows if the dataset meets your agency’s data quality standards if any apply.
Please note that in the License field, if applicable, the URL for the license should be provided.
Spatial. If the dataset is about a specific location, enter that information in this field.
Temporal. If the dataset covers a specific date range, enter that information following the format provided.
Theme. Enter words for themes or categories. This supports search and faceted viewing of datasets.
Data Dictionary. If there is a data dictionary or schema for the dataset, provide the URL here.
Described by Type. Choose the data dictionary type from the formats listed.
Accrual Periodicity (Frequency). Choose the frequency from the options listed.
Conforms to (Data Standard). If there is an applicable data standard, enter the URL here.
Landing Page (Homepage URL). If there is a landing page/home page associated with the dataset, enter the URL here.
Language. The default language for datasets is English. If the dataset is presented in another language, select it here.
Primary IT Investment UII. If there is IT Unique Investment Identifier associated with the dataset, enter it here.
References (Related Documents). URLs for additional related resources can be entered here. Multiple URLs can be entered separated by commas.
Issued (Release Date). Enter the release date in the date format provided.
System of Records. If there is a Privacy Act System of Records Notice (SORN) associated with the dataset, enter the URL for the published SORN here.
The last two fields are to indicate if this dataset is part of a collection or if you want to designate this dataset as the “parent” of a collection.
Is parent. Yes or No. If you want to make this dataset the “parent” of a collection, choose yes. Otherwise choose no.
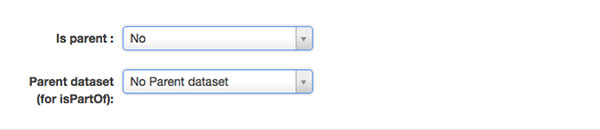
Note that once you make a dataset a “parent” dataset, it cannot be a “child” dataset, or part of another collection of datasets. After a dataset is selected as parent, this dataset will be available for the subsequent datasets in this organization to choose a parent dataset (for isPartOf)
If you chose No and made the dataset a non-parent dataset, you would then be able to choose in the next field (Parent dataset) – the datasets that you want to make this dataset as part of a collection, note that this field is optional and can be left empty if you would like the dataset to be an independent dataset.
Once you are finished entering the metadata, hit Next: Add Data on the bottom right.
You are then taken to another screen with more fields about accessing the dataset.
For most inventory.data.gov users, the dataset is actually hosted on the agency.gov site, so you will hit the “Link to a file” radio button and provide the URL. If you would like to provide a link to API, choose the “Link to an API” radio button, provide the URL, and enter the value “API” in the format field, to provide a web page URL where dataset information is available user the radio button option “Access URL.”
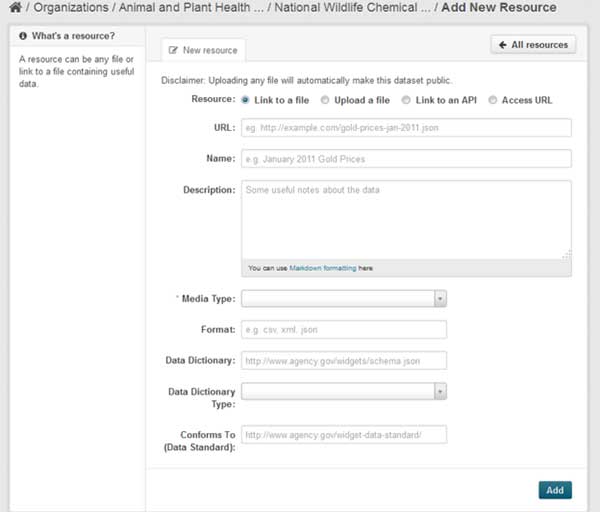
Provide a description of the dataset.
Media type. Choose the relevant format.
Format. Type in the format in this field. (API value for “Link to API” option)
Draft Feature
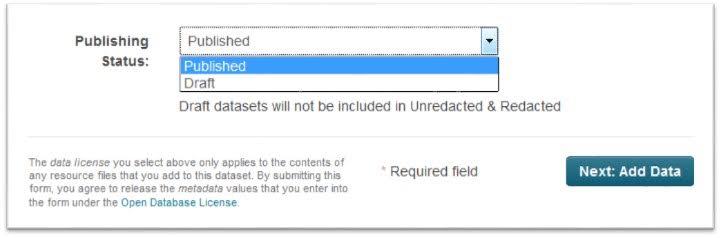
While creating datasets in inventory.data.gov, users can set the “Publishing Status” value as “Draft,” which indicates that the dataset is still being worked on or reviewed. Any dataset saved with “Draft” status will not be included in the generated Redacted/Unredacted data.json files. The draft feature allows users to enter preliminary data and finalize the dataset at a later point by changing the “Publishing Status” value to “Published.”
Clone Feature
Users can create a clone of a particular dataset by clicking on the “Clone” button displayed on the top right of the dataset page. The Clone feature is useful if you are entering lots of datasets manually, and most of the metadata like Bureau Code, Program Code, Publisher Name, Contact Name etc. is the same for all of them.
After you click on the Clone button, make sure to correct the Dataset title and Unique Identifier at a minimum on the cloned dataset, and review all the other field values to make sure they are correct before updating the dataset.
Please note that resources like the CSV file uploaded or linked to the original dataset will not be cloned as it is expected that resources will be different for the cloned datasets. Resources need to be entered manually for the cloned datasets.

Exporting Data.json
Once you have finished entering and editing the metadata for your organization, you are ready to export the datasets to generate the data.json files which comply with Project Open Data Schema 1.1 version. This is done from the main Organization page, by clicking on your agency Organization icon on the left or by clicking on your agency Organization name on the top of the page.
There are three choices at the top.
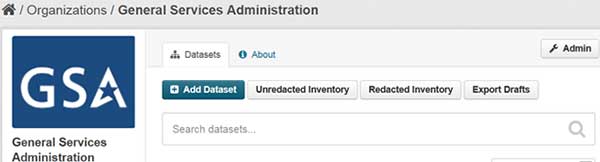
The Redacted Inventory button (formerly labeled Public Data Listing) will give you the redacted inventory of all of the datasets from your organization. This is the listing that you will post on your agency.gov/data.json and will be harvested by the Data.gov catalog to populate your organization’s listing in Data.gov catalog.
The Unredacted Inventory (formerly labeled Enterprise Data Inventory) button will give you a file of all of your organization’s datasets without any redactions. This is the file that is submitted to OMB and is not publicly shared unless an agency has made the decision to share it.
The Export Drafts button will export all datasets that are currently in “draft” status to a file.
The process for each is the same. Depending on your browser, clicking the button will either give you a prompt to open or save the file or it will be downloaded automatically.
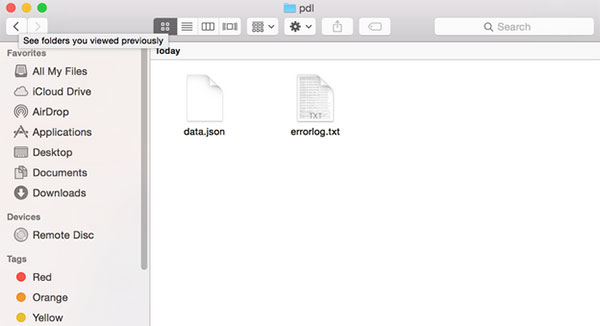
The file that is delivered is a zip file. It contains both the data.json and (if errors were found) an errorlog.txt and errors.json file.
| It is very important to make sure that all datasets were successfully exported when downloading the Unredacted (EDI) or Redacted (PDL) data.json file. This can be done by checking to make sure that an errorlog.txt file was not included in the zip file. If there are errors in the errorlog.txt file, those need to be reviewed and resolved before posting the Redacted (PDL) data.json file in the agency.gov/data.json location. This is critical. Ignoring this step can potentially remove datasets from data.gov since they will no longer be present in the data.json file. Metadata that is directly entered into inventory.data.gov will be validated when the information is first entered, however some invalid metadata may have been imported directly into inventory.data.gov and will not be checked until this final export. The data.gov team is aware that this is not very user friendly or streamlined way of indicating which datasets need to be fixed and is in the process of improving inventory.data.gov so that these errors can be viewed directly on the inventory.data.gov website rather than as a separate log file. However, for now it is very important to review this file as explained earlier. |
The errorlog.txt will describe the datasets that did not validate against the Project Open Data Schema as needed to be included in the data.json file. If there were no errors encountered in creating the data.json, then errorlog.txt file will not appear in the zip file.
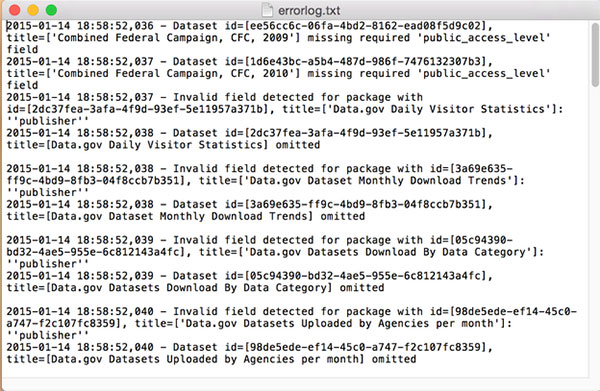
The error log indicates the type of problem, the dataset ID, and the dataset title, so that you can find the problematic dataset in inventory.data.gov and fix the problem. Search for the dataset, choose Edit, and make the required changes.
Once you fix the errors, go back to the Organization page and re-download the Redacted Inventory (PDL) or Unredacted Inventory (EDI) datasets, and you should get a zip file with just the data.json and no error log.
For the Unredacted Inventory (EDI), the data.json file can be submitted to OMB Max. For the Redacted Inventory (PDL), the data.json will need to be posted on the agency’s website at agency.gov/data.json in order to be harvested by the Data.gov catalog. If the data.json is being posted on the agency.gov website for the first time, please contact the Data.gov team via email to set the harvest source on catalog.data.gov.
Automating data.json downloads by agencies
Rather than log in to inventory.data.gov and manually click the buttons to download the Redacted Inventory (PDL) and Unredacted Inventory (EDI) files, it is possible to use the API and your API key in order to automate the process of adding the data.json file to the agency website.
Here’s what the request would look like using the curl-like tool httpie
Redacted Inventory (PDL)
http -v POST https://inventory.data.gov/organization/[organization-id]/redacted.json
Authorization:xxx-your-api-key-xxx
Content-Type:application/x-www-form-urlencoded
Cookie:auth_tkt=foo
Unredacted Inventory (EDI)
http -v POST https://inventory.data.gov/organization/[organization-id]/unredacted.json
Authorization:xxx-your-api-key-xxx
Content-Type:application/x-www-form-urlencoded
Cookie:auth_tkt=foo
You’d need to replace xxx-your-api-key-xxx with your actual API key which you can get in the bottom of the left sidebar of your user account, e.g. https://inventory.data.gov/user/[username]
The above process downloads the Redacted.zip file containing the data.json and errorlog.txt. If there are any errors, you should review and correct them. When you reach a point where there is no errorlog.txt file, you can upload the data.json file to the agency.gov/data.json public data listing for data.gov catalog harvesting purposes. It is recommended that you manually review and upload the data.json file a few times, before completely automating the entire process to ensure there are no errors that might be excluding datasets from the data.json file (potentially removing existing datasets from data.gov).
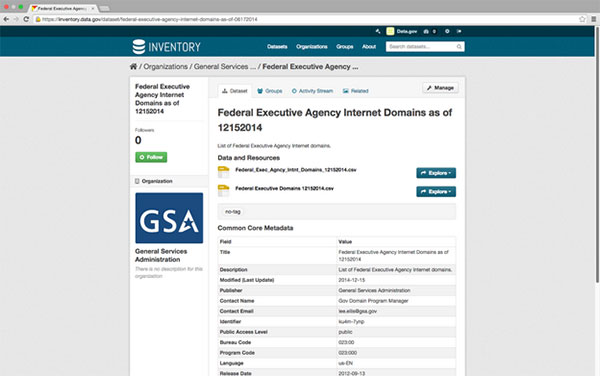
Dataset Hosting
The primary use of inventory.data.gov is to provide a dataset management system for agencies that need a tool to meet the requirements of the Open Data Policy. It is a separate instance of CKAN and requires a user account and password.
Data.gov uses inventory.data.gov for a second purpose. From 2011-2014, Data.gov featured data hosting using the Socrata platform at explore.data.gov. About a dozen agencies used explore.data.gov to host their datasets directly on Data.gov. At the conclusion of the Socrata task order in 2014, several agencies indicated a continuing need for hosting capability for these datasets (approximately 100). To accommodate these agencies, the Data.gov PMO migrated the datasets previously hosted at explore.data.gov to a hosting capability using the CKAN DataStore extension, on the CKAN instance at inventory.data.gov. As a result, the access URLs for this small number of datasets begin with inventory.data.gov and are publicly accessible without needing a user account.
For the time being, the Data.gov PMO will continue to provide this hosting capability on inventory.data.gov while it remains small scale and does not require significant additional Data.gov resources.
Webinar on inventory.data.gov
Data.gov, working with DigitalGov University, presented a webinar for agencies interested in using inventory on December 16, 2014. For more information, consult the recording of the webinar.
Here are some questions and answers raised during the webinar:
- If your agency already has an admin listed, do you need their approval to be appointed as an admin?
If someone at your agency already has an admin account on inventory.data.gov, that person can grant you an admin account. There are no limits on how many admin accounts an agency can have.
- Who do we email to request our organization be created?
Contact the DataGov team via email.
- Who should I contact to get my organization approved/created?
When you contact the Data.gov team (see contact info above) about using inventory.data.gov, we can create the organization for you.
- For the record to be identified as geospatial, does “geospatial” go in Theme (Category)
Yes. That designation also ensures that record is included in geoplatform.gov.
- Is there a way to import an existing data.json into inventory.data.gov?
For importing existing data.json, please contact the Data.gov team and we will work with you to migrate into inventory.data.gov.
- How do we know our agency POC?
For Data.gov/Open Data Policy purposes, if you don’t know your agency’s POC, contact the Data.gov team and we will connect you. You can also find your agency POC at https://project-open-data.cio.gov/points-of-contact/
- How does this work with Data.gov?
Inventory.data.gov is a separate system from the Data.gov catalog, using the same technology as the catalog (CKAN) to provide a service that agencies can use to create and maintain data inventories that are ultimately harvested by the Data.gov catalog from agency.gov/data.json
- Can we add custom core metadata fields?
Yes, but not through the user interface on inventory.data.gov currently. Please contact the Data.gov team if you have this situation.
- Does search works only on dataset name and description or the actual content as well?
Search does not cover the actual content.
- What is the difference between public and restricted-public?
See the “access level” field in Project Open Data: The degree to which this dataset could be made publicly-available, regardless of whether it has been made available. Choices: public (Data asset is or could be made publicly available to all without restrictions), restricted public (Data asset is available under certain use restrictions), or non-public (Data asset is not available to members of the public).
- Can you clarify the difference between central and inventory CKAN? It seems like many datasets are using the datastore feature on inventory.data.gov – is this no longer the policy and inventory is mainly for creating data.json files?
“Central CKAN” was a term used in 2014 to refer to what we call inventory.data.gov – it is one and the same. This webinar focused on the primary purpose of inventory.data.gov – to provide a dataset management system to help agencies create and maintain their data inventories and arrive at a data.json. We do use inventory.data.gov for a second purpose – to host a small number of datasets for agencies that needed a hosting capability at the conclusion of the Socrata platform contract that Data.gov had until July 2014.
- If inventory.data.gov is not intended for geospatial metadata, what system is? Geoplatform.gov? If we have standards-compliant (ISO, FGDC, etc.) metadata already published, can we import these metadata fields? Or must we enter them manually?
Inventory.data.gov in its current form is not designed to handle geospatial metadata. As discussed in our harvesting documentation, Data.gov continues to harvest geospatial datasets directly from geospatial harvest sources. Agencies should have the remainder of their agencies in a “non-geospatial” data.json that the Data.gov catalog can harvest.
- So the system does not push errors to you; you have to search for them?
When you are ready to export your agency’s datasets to data.json and hit the button on inventory.data.gov, you will be prompted to download a zip file containing the data.json. If there are errors, the zip file will also contain an error log containing information about the datasets with errors. We are working on improving validation within inventory.data.gov so that more errors are identified as you are adding and editing datasets, before you reach the export stage.